Wow really? That's kind of a shitty stance for them to take.
this post was submitted on 23 Aug 2024
129 points (100.0% liked)
Piracy: ꜱᴀɪʟ ᴛʜᴇ ʜɪɢʜ ꜱᴇᴀꜱ
54716 readers
378 users here now
⚓ Dedicated to the discussion of digital piracy, including ethical problems and legal advancements.
Rules • Full Version
1. Posts must be related to the discussion of digital piracy
2. Don't request invites, trade, sell, or self-promote
3. Don't request or link to specific pirated titles, including DMs
4. Don't submit low-quality posts, be entitled, or harass others

Loot, Pillage, & Plunder
📜 c/Piracy Wiki (Community Edition):
💰 Please help cover server costs.
 |
 |
|---|---|
| Ko-fi | Liberapay |
founded 1 year ago
MODERATORS
True, but sadly the kind of one they must take to avoid being hit with a cease and desist.
They know someone will fork it. Playing it safe is smart
Especially when downloading from the other supported sites (example: YouTube) is already against their tos and technically, piracy
From whom? The piracy site owners?
Copyright troll. They even hit manga reader app. Not even distribute any material, just a reader. Just because can load manga from piracy site.
I don't think a fork will solve anything. I'm pretty sure the reason they did this is to cover their asses (don't forget that it was very near to being taken down just a few years ago).
Further, yt-dlp has implemented plugin support, for this exact reason. I think that's a new feature compared to youtube-dl. You can add your own extractors as plugins, wherever you find them. As I remember there are a few plugins that are even maintained by a yt-dlp maintainer.
If you find this to be ok or better, please consider changing the title to let those know about what's happening who have already read the post, because they wouldn't know it otherwise.
See https://forums.freebsd.org/threads/yt-dlp-error-piracy-this-website-is-no-longer-supported.93995/ for some pertinent comments.
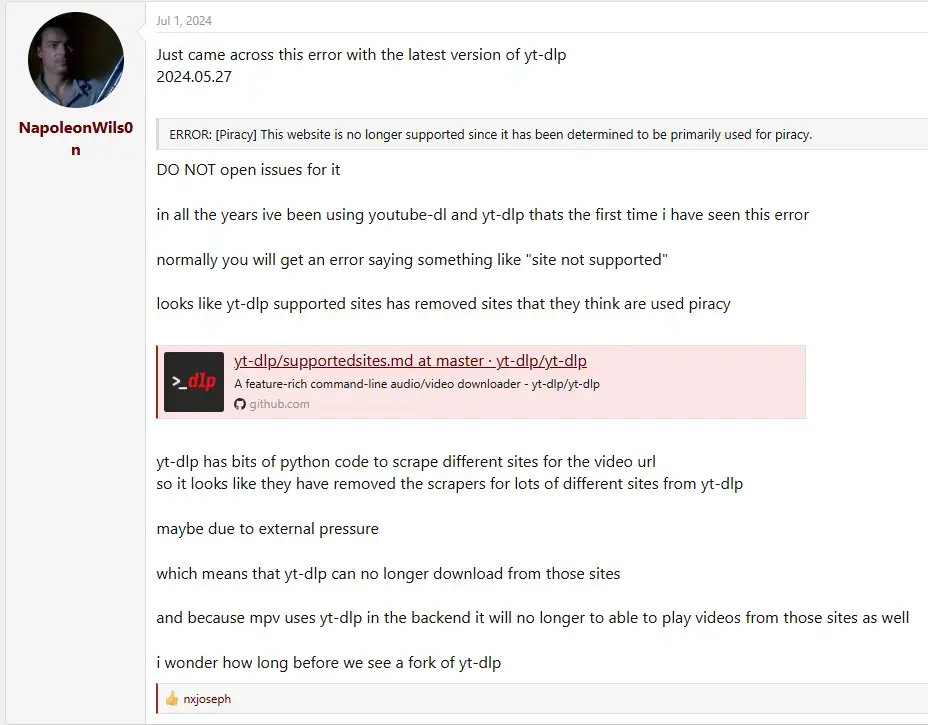
See list of forks here https://github.com/yt-dlp/yt-dlp/forks. If you find one that works, let us know.
Can you remember the last version that worked for you? A quick workaround could be downloading an older build off the github.
Still this is extremely disappointing and hopefully someone forks it.
It used to work last year 😀 . The debian yt-dlp version: stable@2023.03.04 is giving a different error
ERROR: [Einthusan] 9r1H: 9r1H: Failed to parse JSON (caused by JSONDecodeError("Expecting value in '': line 1 column 1 (char 0)")); please report this issue on https://github.com/yt-dlp/yt-dlp/issues?q= , filling out the appropriate issue template. Confirm you are on the latest version using yt-dlp -U
Old versions of yt-dlp never work for me. Even after a few months, it's usually time to upgrade.
Time to fork it with a non pussyfied version
A plugin for yt-dlp will suffice. It's also easier to maintain.
Maybe you can find some more discussion and the reasoning in their documentation or Github issues or pull requests. I bet this has been discussed before someone implemented it. Maybe there's also a way to restore the old behaviour.
There is, they added plugin support. See my top level comment for details
This isn't going to make the copyright holders hate them any less.
But it IS giving the copyright holders less attack surface to bite into. Haters gonna hate, let them.
The most likely explanation is that their previous implementation broke due to a website change, and they didn't want to bother with fixing it. People began opening issues for them to fix it, but now it looks like they're aiding people explicitly asking for piracy, so they can't win (and also I'm willing to bet it fucking sucked trying to support that particular website)
Is that an indirect plea to open an issue for it? We should do this.
They are closing all issues citing piracy https://github.com/yt-dlp/yt-dlp/issues?q=is%3Aissue+piracy+is%3Aclosed
Could be a liability for them to have to work on support for those sites when it breaks.
Sounds like its time for a pirate fork... maybe yt-dlpirate?
I mean, fuck it, one of the big private trackers could do releases, kind of like how Bibliotik does releases of those tools to strip DRM from ebooks.
some way to call a custom or 'third party' (not compiled into the program) extractor would probably be enough. then let other people work on ones for the, um, 'problem sites'.
Right. Site plugins or something.
What sites for eg?