this post was submitted on 28 Jan 2025
1092 points (97.6% liked)
Microblog Memes
9267 readers
3093 users here now
A place to share screenshots of Microblog posts, whether from Mastodon, tumblr, ~~Twitter~~ X, KBin, Threads or elsewhere.
Created as an evolution of White People Twitter and other tweet-capture subreddits.
Rules:
- Please put at least one word relevant to the post in the post title.
- Be nice.
- No advertising, brand promotion or guerilla marketing.
- Posters are encouraged to link to the toot or tweet etc in the description of posts.
Related communities:
founded 2 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
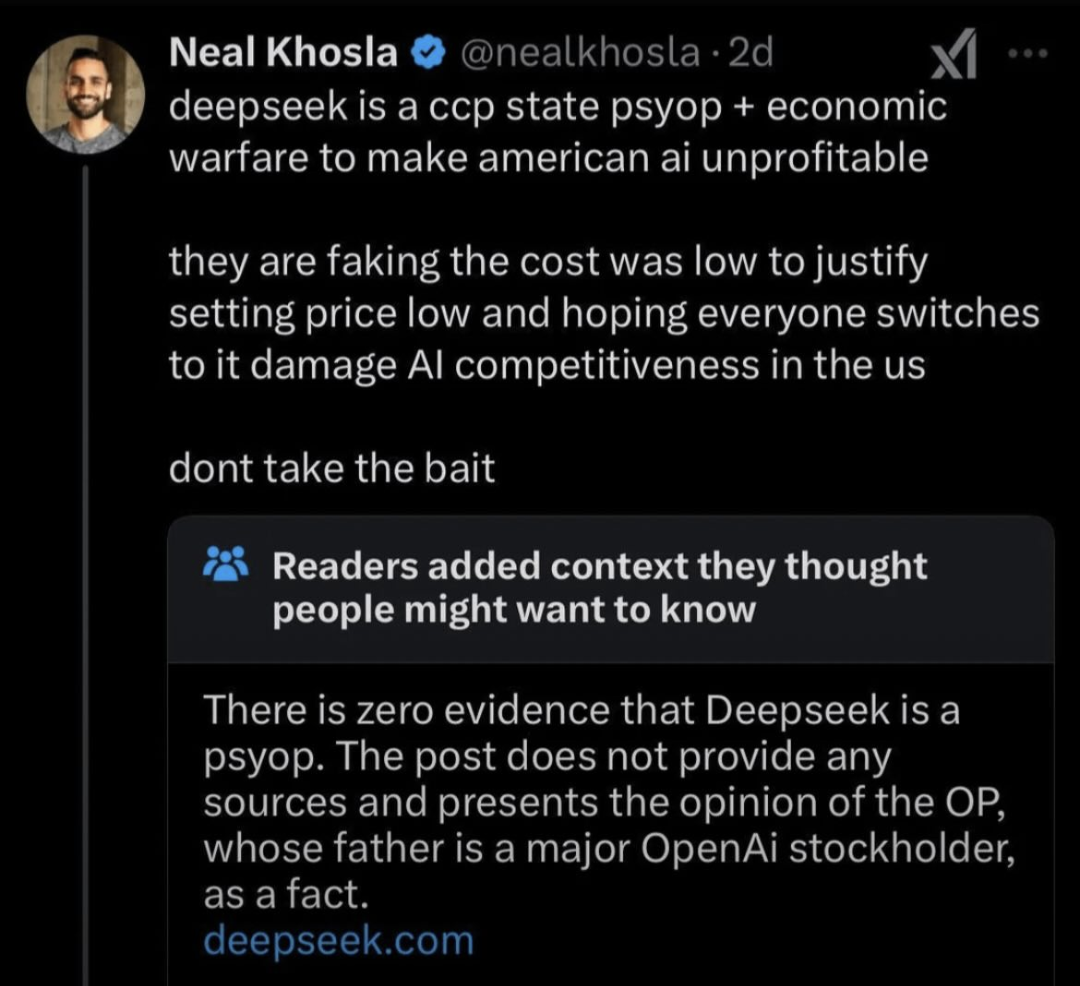
Yes I know but what I'm saying is they're just repackaging something that openAI did, but you still need openAI making advances if you want R1 to ever get any brighter.
They aren't training on large data sets themselves, they are training on the output of AIs that are trained on large data sets.
Oh I totally agree, I probably could have made my comment less argumentative. It's not truly revolutionary until someone can produce an AI training method that doesn't consume the energy of a small nation to get results in a reasonable amount of time. Which isn't even mentioning the fact that these large data sets already include everything and that's not enough. I'm glad that there's a competitive project even if I'm going to wait a while and let smarter people than me sus it out.