this post was submitted on 28 Jan 2025
1079 points (97.5% liked)
Microblog Memes
6328 readers
4298 users here now
A place to share screenshots of Microblog posts, whether from Mastodon, tumblr, ~~Twitter~~ X, KBin, Threads or elsewhere.
Created as an evolution of White People Twitter and other tweet-capture subreddits.
Rules:
- Please put at least one word relevant to the post in the post title.
- Be nice.
- No advertising, brand promotion or guerilla marketing.
- Posters are encouraged to link to the toot or tweet etc in the description of posts.
Related communities:
founded 2 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
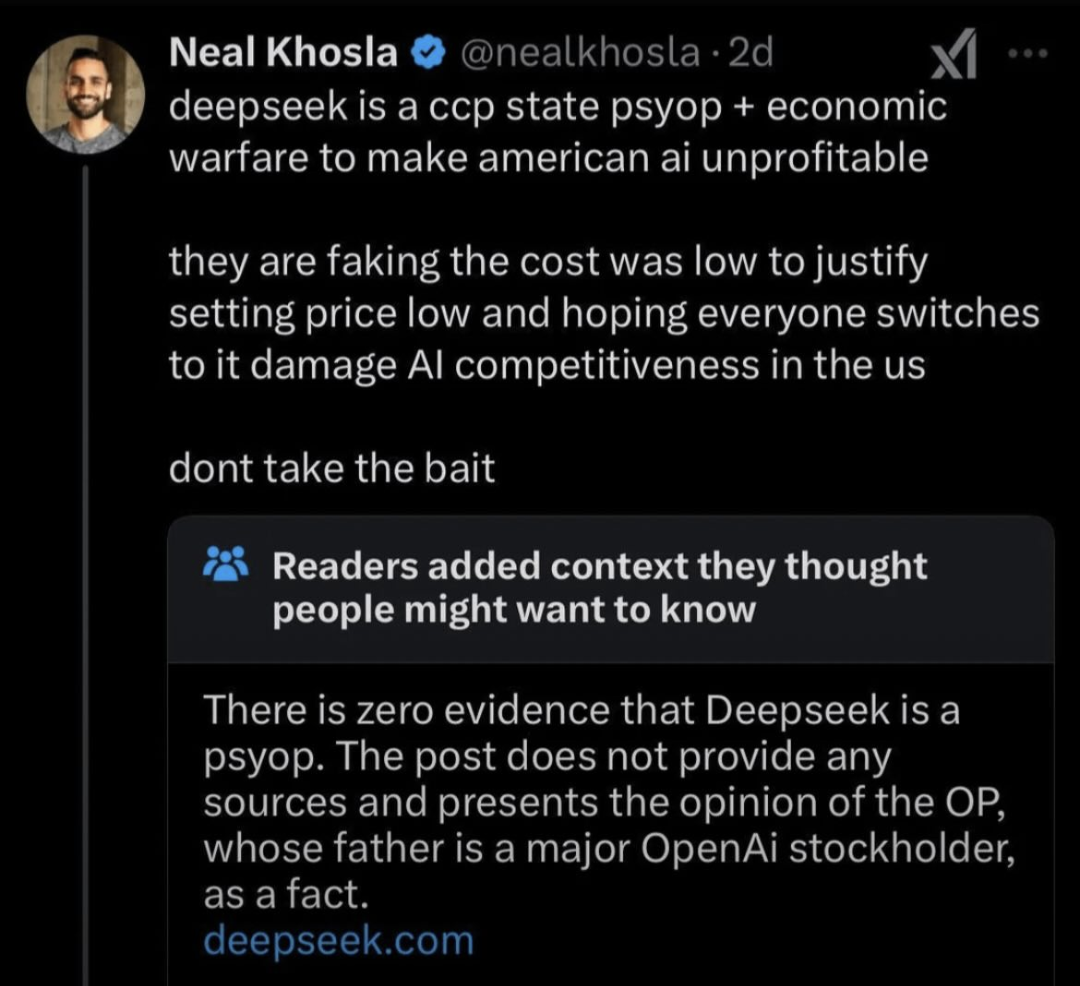
The actual local model for R1 (the 671b one) does give that output because some of the censorship is baked into the training data. You're probably referring to the smaller parameter models which don't have that censorship--because those models are distilled versions of R1 based on llama and qwen (the 1.5b, 7b, 8b, 14b, 32b, and 70b versions)
You can see a more in-depth discussion of that here: trigger warning: neoliberal techbros